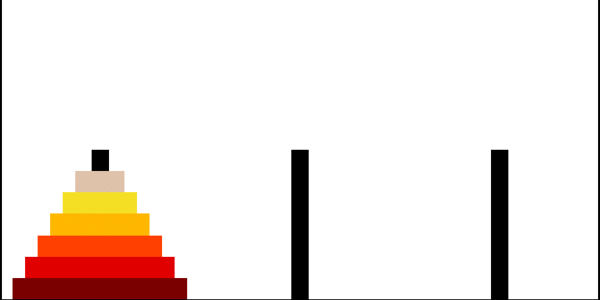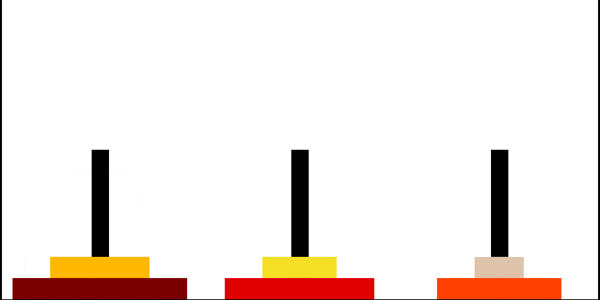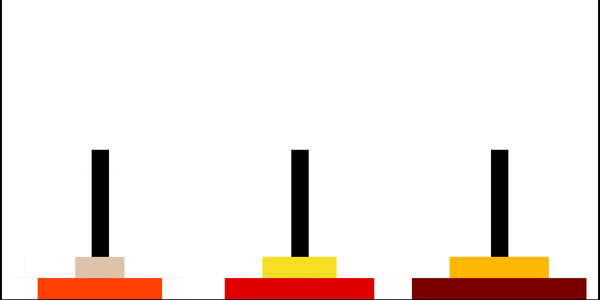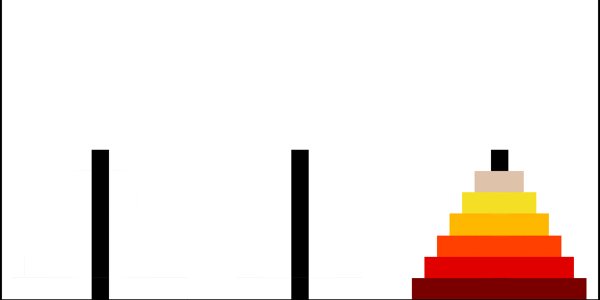Рекурсия
Рекурсия вокруг нас
Если рассматривать понятие общо, то рекурсия – это ситуация, когда объект является частью себя.
Например, при демонстрации экрана на камеру в прямом времени. Ведь тогда камера снимает экран, на котором видно экран, на котором видно экран, на котором видно экран и так далее. Это пример бесконечной рекурсии.
Еще один пример бесконечной рекурсии – это фрактал – самоподобный объект. Например, так выглядит треугольник Серпинского:

 Итерации при построении треугольника Серпинского
Итерации при построении треугольника Серпинского
В математики последовательности можно задать рекуррентной формулой. Например, известная нам последовательность Фибоначчи задается именно таким образом:
\[ \begin{cases} F_1 = 1 \\ F_2 = 1 \\ F_n = F_{n - 1} + F_{n - 2}, n > 2 \end{cases} \]
Рекурсия в программировании
Рекурсия в программировании – вызов функции из нее же самой. Чаще всего применяется в:
- обработке графов (не будет рассмотрено в нашем курсе) – запускаем функцию из некоторой вершины. Она запускает себя же от соседней вершины. Так возникает рекурсия
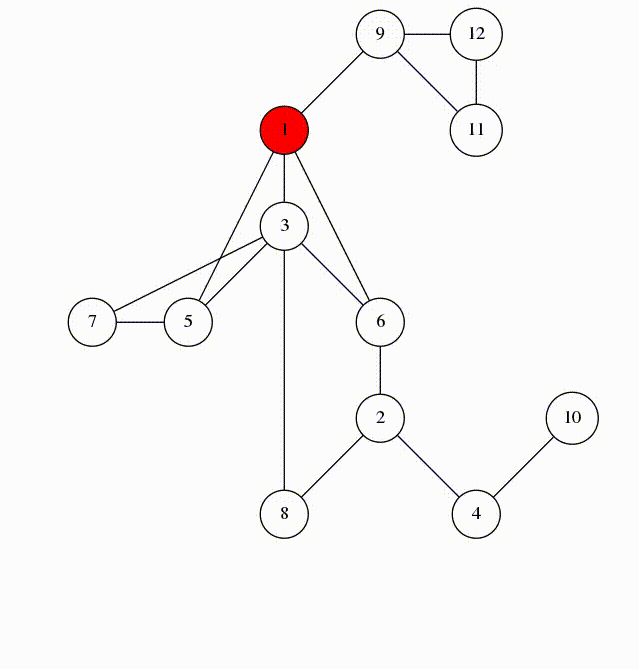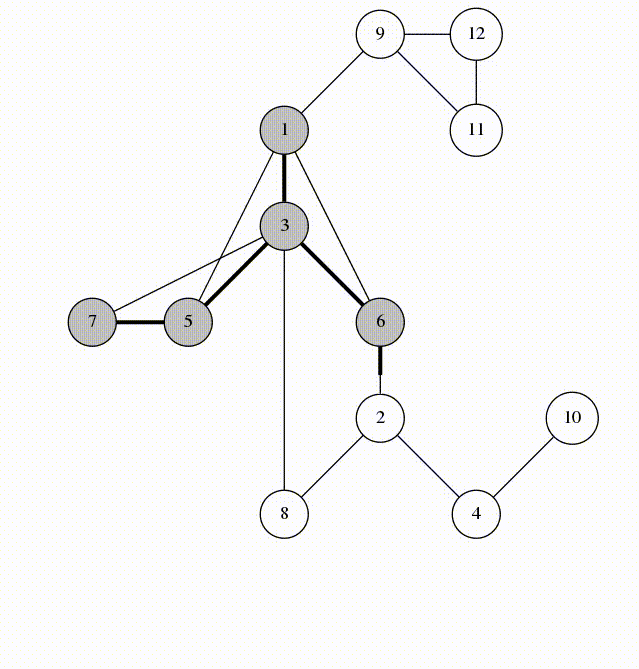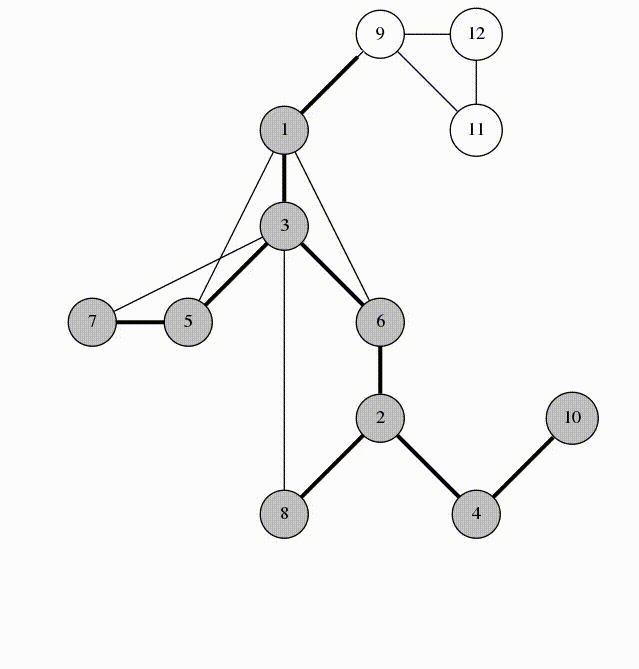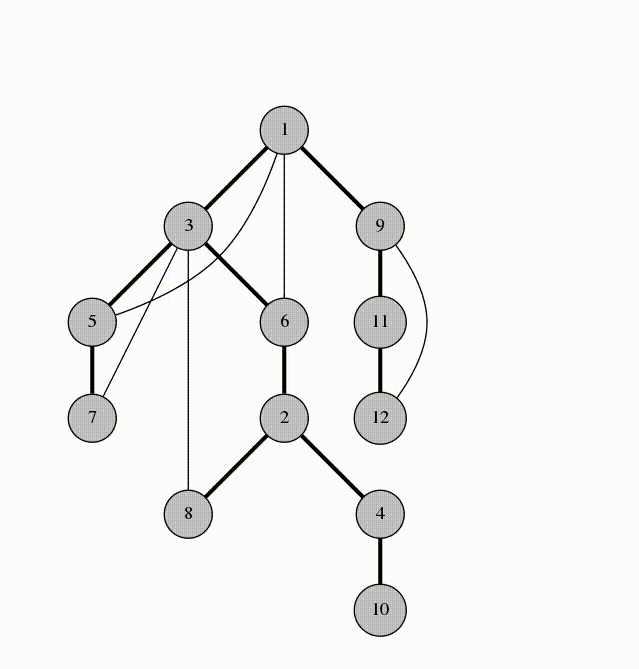 Обход графа в глубину – DFS
Обход графа в глубину – DFS
генерации перестановок, всех слов в алфавите. Почему? Если мы хотим все слова длины \(n\), то их можно получить, подставив все возможные буквы к каждому из слов длины \(n - 1\) – снова возникла рекурсия
сортировки. Чтобы отсортировать массив длины \(n\), можно разбить его на 2 половины и отсортировать каждую из них, а затем некоторым образо их совместить.
более сложные случаи применения рекурсии, которые не будут разбираться на курсе. Например, рекурсия может использоваться при построении выпуклой оболочки набора точек
Что общего у основных случаев рекурсии? Это сведение большой задачи к нескольким таким же подзадачам на меньших данных.
Нахождение суммы рекурсивно
Перейдем к более конкретным примерам и рассмотрим нахождение суммы элементов массива с помощью рекурсивной функции.
- Как разбить задачу на подзадачи? Заметим, что сумма массива длины \(n\) – это сумма первого элемента и всех остальных (то есть суммы массива длины \(n - 1\)). Более формально:
\[ \sum_{i = 1}^{n} a_i = a_1 + \sum_{i = 2}^{n} a_i = a_1 + \left( a_2 + \sum_{i = 3}^{n} a_i \right) = a_1 + (a_2 + (a_3 + \dots \ ) \dots ) \]
Тогда пусть \(\operatorname{sum}(i, j)\) – сумма элементов от \(i\)-того до \(j\)-того включительно. Тогда можем записать сумму следующим образом:
\[ \operatorname{sum}(i, j) = a_i + \operatorname{sum}(i + 1, j) \]
- Когда рекурсия должна остановиться? Это очень важный вопрос, ведь иначе рекурсия будет запускаться бесконечно, чего мы не хотим. Очевидный случай суммы массива – это когда массив состоит из одного элемента. Действительно, тогда этот единственный элемент и является всей суммой. Запишем это в нашу рекурсию:
\[ \operatorname{sum}(i, j) = \begin{cases} a_i + \operatorname{sum}(i + 1, j), \text{\ если \ } i \ne j \\ a_i, \text{\ если \ } i = j\pm \end{cases} \]
Затетим, что условие выхода (а именно его мы сейчас определили) может быть различным, например, такое задание рекурсии также будет корректно работать:
\[ \operatorname{sum}(i, j) = \begin{cases} 0, \text{\ если \ } i > j \\ a_i + \operatorname{sum}(i + 1, j), \text{\ иначе \ } \end{cases} \]
#include <iostream>
#include <vector>
int recursive_sum(const std::vector<int>& nums, int start, int stop) {
std::cout << "finding sum of " << start << " to " << stop << '\n';
if (start == stop) {
std::cout << "found sum of " << start << " to " << stop << ": " << nums[start] << '\n';
return nums[start];
}
std::cout << "finding sum of " << start << " to " << stop << " by summing " << start
<< " and sum of " << start + 1 << " to " << stop << '\n';
return nums[start] + recursive_sum(nums, start + 1, stop);
}
int main() {
std::vector<int> nums = {1, 2, 3, 4};
std::cout << recursive_sum(nums, 0, nums.size() - 1) << '\n';
return 0;
}finding sum of 0 to 3
finding sum of 0 to 3 by summing 0 and sum of 1 to 3
finding sum of 1 to 3
finding sum of 1 to 3 by summing 1 and sum of 2 to 3
finding sum of 2 to 3
finding sum of 2 to 3 by summing 2 and sum of 3 to 3
finding sum of 3 to 3
found sum of 3 to 3: 4
10Более C++ный способ написать такую рекурсию – это использовать итераторы. Передаем итераторы на начало и конец контейнера:
#include <iostream>
#include <vector>
#include <unordered_set>
template<typename T>
int recursive_sum(T begin, T end) {
if (begin == end) {
return 0;
}
return *begin + recursive_sum(++begin, end);
}
int main() {
std::vector<int> nums = {1, 2, 3, 4};
std::cout << recursive_sum(nums.begin(), nums.end()) << '\n';
std::unordered_set<int> nums_set = {1, 2, 3, 4};
std::cout << recursive_sum(nums_set.begin(), nums_set.end()) << '\n';
return 0;
}10
10В последнем примере стоит обратить внимание, что аргументы передаются в функцию recursive_sum по значению, а не по ссылке, так как копирование итератора, как и указателя, как и любого встроенного типа (int, bool, char) не является сложной операцией.
В выражении recursive_sum(++begin, end) применяет именно прединкремент, так как он применяет до выполнения выражения, в котором он применяет. При использовании постинкремента функция бы не имела смысла
Последнее замечании – о применимости такого рекурсивного подхода. Можно заметить, что так можно применять любую ассоциативную функцию (на итог выражения с которой не влияет расстановка скобок: \(a + b + c = (a + b) + c = a + (b + c)\) ). К таким можно отнести, например, операцию взятия максимума:
\[ \max (a, b, c) = \max (\max(a, b), c) = \max (a, \max(b, c)) \]
Общая рекомендация при работе с рекурсией
Для корректного написания рекурсии нужно:
свести задачу к набору меньших подзадач, после решения которых можно простым действием перейти к ответу на исходную задачу
проследить за ходом рекурсии и определить условие выхода – это тот примитивный случай, когда для ответа запуск рекурсии не требуется
проверить, что рекурсия всегда попадает в одно из условий выхода
Для облегчения рассуждений, можно считать, что функция уже написана и является черным ящиком – мы так делали, когда только начинали работать с функциями. Написав функцию, мы не думали о ее реализации, а просто использовали в остально программе как “черный ящик”. Здесь можно применить похожее рассуждение, только уже при написании самой функции. Например, в реализованной выше фукции recursive_sum(begin, end) мы верили, что она как-то находит сумму, и смело запускали ее на меньшем массиве, веря в корректную работу.
Рекурсия при работе с цифрами числа
Найдем максимальную цифру числа.
Сведение к подзадачам
Максимальная цифра всего числа: найдем максимум из последней цифры числа и максимумом из всех остальных цифр.
Более формально, \(\operatorname{max\_digit}(N) = \max (N \% 10, \operatorname{max\_digit}(N / 10))\), где \(\%\) и \(/\) – взятие остатка и целочисленное деление соответственно
Условие выхода
Если перед нами число из одной цифры, то она и будет наибольшей среди всех цифр этого числа.
Алгоритм Евклида
источник описания алгоритма Евклида
Классический алгоритм, который можно решать с помощью рекурсии – это алгоритм Евклида для нахождения НОД двух чисел (наибольшего общего делителя).
Наибольшим общим делителем (англ. greatest common divisor) целых неотрицательных чисел \(a\) и \(b\) называется наибольшее число \(x\), которое делит одновременно и \(a\), и \(b\). Когда оба числа равны нулю, результат не определён — подойдёт сколько угодно большое число. За исключением этого случая, верно следующее наблюдение: если одно из чисел равно нулю, то их \(\gcd\) равен второму числу.
Алгоритм нахождения
Алгоритм Евклида находит \(\gcd\) двух чисел \(a\) и \(b\) за \(O(\log \min(a, b))\), основываясь на следующей несложной формуле:
\[ \gcd(a, b) = \begin{cases} a, & b = 0 \\ \gcd(b,\, a - b), & b > 0 \end{cases} \]
Здесь предполагается, что \(a > b\).
Докажем корректность этой формулы:
Если \(g = \gcd(a, b)\) делит и \(a\), и \(b\), то их разность \((a-b)\) тоже будет делиться на \(g\).
Никакой больший делитель \(d\) числа \(b\) не может делить число \((a-b)\): если \(d > g\), то \(d\) не может делить \(a\), а значит и не делит \((a - b)\).
Прямая рекурсивная реализация:
int gcd(int a, int b) {
if (a < b) {
std::swap(a, b);
}
if (b == 0) {
return a;
}
return gcd(b, a - b);
}Этот алгоритм может работать долго — например, на паре \((10^9, 1)\) он сделает миллиард итераций.
Идея дальнейшей оптимизации в том, чтобы вычитать из \(a\) не одно \(b\) за раз, а столько, чтобы в следующий раз \(a\) и \(b\) уже поменялись местами — чтобы новое \(b\) стало меньше нового \(a\). Простой способ этого достичь — просто вычесть \(b\) из \(a\) сразу максимально возможное число раз, то есть взять вместо нового \(b\) остаток от деления \(a\) на \(b\):
\[ \gcd(a, b) = \begin{cases} a, & b = 0 \\ \gcd(b,\, a \bmod b), & b > 0 \end{cases} \]
В домашнем задании вам предстоит реализовать разобранный рекурсивный алгоритм самостоятельно.
Часто рекурсию можно заменит на итеративный алгоритм, например:
int gcd(int a, int b) {
while (b > 0) {
a %= b;
swap(a, b);
}
return a;
}В современном C++ есть встроенная библиотечная функция std::gcdиз хэдера <numeric>, которую рекомендуется использовать, не забывая про случай отрицательных чисел и \((0, 0)\). Эта функция уже могла использоваться на курсе в одной из домашних задач.
Время работы
Можно показать, что каждые две итерации меньшее число уменьшится хотя бы в два раза, а следовательно алгоритм работает за \(O(\log \min (a, b))\). Эта оценка относится не только к худшему случаю, но и к среднему.
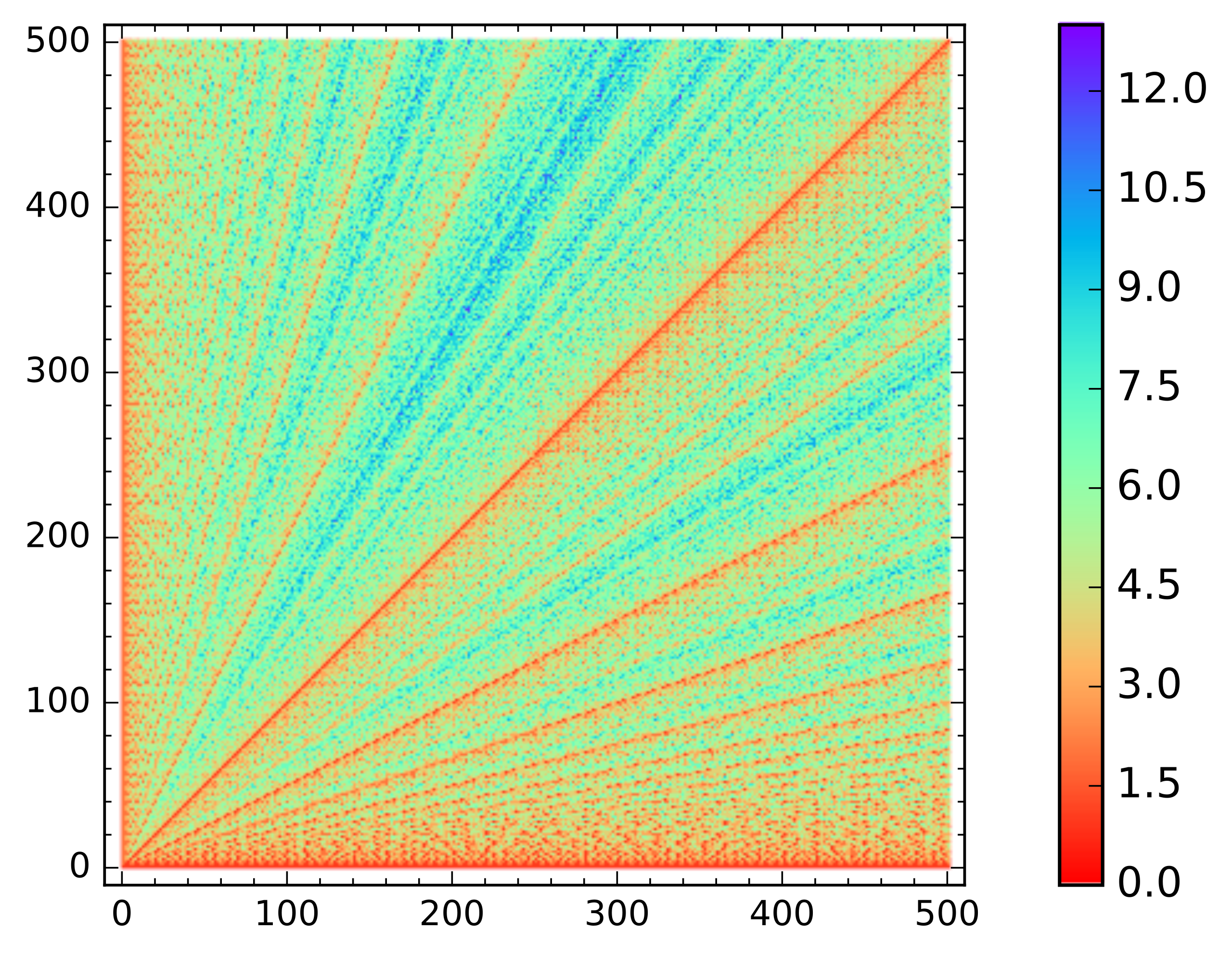
Примечательно, что худшие входные данные для алгоритма — это соседние числа Фибоначчи. На графике они видны как синие точки в пропорциях золотого сечения.
Также иногда полезно знать, что нахождение \(\gcd\) группы из \(n\) чисел от \(1\) до \(A\) будет работать не за \(O(n \log A)\), а за \(O(n + \log A)\) — это несложно доказать по индукции.
Ханойские башни
Ханойская башня — перестановочная головоломка в виде трёх стержней, на один из которых в виде пирамиды нанизаны восемь колец разного диаметра. Задача состоит в том, чтобы переместить пирамиду из колец на другой стержень за наименьшее число ходов. За один раз разрешается переносить только одно кольцо, причём нельзя класть большее кольцо на меньшее.
Рекурсивное решение для произвольного количества колец
Рекурсивно решаем задачу «перенести башню из \(n−1\) диска на \(2\)-й стержень». Затем переносим самый большой диск на \(3\)-й стержень, и рекурсивно решаем задачу «перенеси башню из \(n−1\) диска на \(3\)-й стержень».
Отсюда методом математической индукции заключаем, что минимальное число ходов, необходимое для решения головоломки, равно \(2^n − 1\), где \(n\) — число дисков.